

Boas-vindas! Meu nome é Valquíria Alencar, sou instrutora na escola de Dados da Alura, e irei te acompanhar ao longo dessa jornada de aprendizagem.
Audiodescrição: Valquíria se descreve como uma mulher branca, de olhos castanho-escuros, cabelos loiros e ondulados abaixo dos ombros, e sobrancelhas castanho-escuras. Ela usa um piercing prateado no septo, tem tatuagens em ambos os braços, veste uma camisa rosa-clara com estampa em tons de rosa e azul, e está sentada no estúdio da Alura, com uma parede clara ao fundo iluminada em gradiente azul e ciano, uma planta à direita da instrutora, e uma estante preta à esquerda com enfeites, plantas, livros e pontos de iluminação amarela.
Neste curso, vamos praticar a criação de gráficos em Python, especificamente, gráficos de distribuição. Para isso, temos um notebook pronto, que vamos executar ao longo da aula. Você pode consultá-lo posteriormente, na atividade após este vídeo.
Usaremos a ferramenta do Google Colab.
Começamos carregando os dados. Para isso, primeiro importamos a biblioteca Pandas (pandas). Depois, lemos um arquivo CSV (pd.read_csv()) e armazenamos na variável df. Por fim, verificamos as cinco primeiras linhas com df.head().
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/alura-cursos/python_dados/refs/heads/main/Dados/loja_vendas.csv')
df.head()
Retorno da célula:
ID_compra | unidade | cidade | data | horario | categoria_produto | valor_unitario | quantidade | valor_total | metodo_pagamento | ID_cliente | programa_cashback | idade | avaliacao_compra |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 6 | Parque das nações | Santo André | 2022-01-03 | 15:40 | Eletrônicos | 4457.9 | 4 | 17831.6 | Dinheiro | 6149 | Sim | 30 | 10 |
| 5 | Oswaldo Cruz | São Caetano do Sul | 2022-01-03 | 16:48 | Ferramentas e construção | 115.9 | 1 | 115.9 | PIX | 9491 | Sim | 36 | 9 |
| 9 | Paulicéia | São Bernardo do Campo | 2022-01-03 | 12:08 | Beleza e cuidados pessoais | 68.9 | 2 | 137.8 | Cartão | 5288 | Não | 39 | 9 |
| 4 | Oswaldo Cruz | São Caetano do Sul | 2022-01-03 | 9:29 | Ferramentas e construção | 80.9 | 5 | 404.5 | PIX | 9679 | Sim | 35 | 10 |
| 8 | Parque das nações | Santo André | 2022-01-03 | 13:02 | Beleza e cuidados pessoais | 165.0 | 4 | 660.0 | PIX | 1380 | Não | 50 | 9 |
Os dados retornados são de uma rede de lojas de departamento, incluindo informações sobre vendas, como unidade, data, horário, categoria do produto, valor unitário, quantidade, valor total, método de pagamento; e sobre clientes, como ID, idade e avaliação da compra.
seabornCriaremos gráficos de distribuição para entender como os dados se espalham ao longo de uma variável, útil para identificar padrões e outliers (valores discrepantes). Para criar os gráficos, importaremos a biblioteca seaborn.
import seaborn as sns
Agora, vamos explorar diferentes tipos de gráficos de distribuição, começando com o histograma, que visualiza a distribuição dos dados ao longo de diferentes faixas de valores. Podemos plotar a variável da idade das pessoas clientes (idade) para entender a distribuição demográfica.
Para plotar um histograma, usamos a função histplot() da biblioteca seaborn. Passamos para ela o nome do DataFrame (df) e especificamos a coluna de interesse, no caso, a idade.
Em seguida, definimos o parâmetro bins, que determina os intervalos no gráfico. Nese caso, executamos com bins=10 e, assim, visualizamos o histograma da idade, identificando as faixas de maior concentração entre 35 e 50 anos.
sns.histplot(df['idade'], bins=10)
Retorno da célula
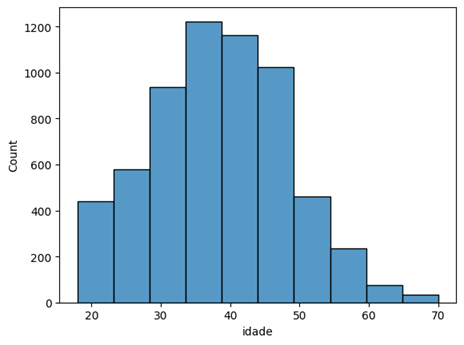
Ao criar um histograma, a ideia é visualizar onde os dados estão mais concentrados, bem como as faixas com menos concentração de informações (no exemplo acima, os menores intervalos estão concentrados na faixa de 20 anos e a partir de 50 anos).
Dica! Um valor muito baixo de
binspode simplificar demais o gráfico, enquanto um valor muito alto pode aumentar a granularidade, dificultando a identificação de padrões.
Podemos usar o parâmetro kde=True no histograma para incluir uma curva de densidade de Kernel, suavizando a distribuição. Isso pode ser interessante para visualizar a suavidade dos dados.
sns.histplot(df['idade'], bins=10, kde=True)
Retorno da célula:

Como resultado, temos uma linha suavizada ao redor dos intervalos do gráfico. Dessa forma, conseguimos verificar exatamente o sentido da distribuição.
Além do histograma, existe o KDE plot, que mostra os dados de forma contínua.
Pra gerar esse gráfico, usamos a função kdeplot(), passando o DataFrame df e a coluna de interesse (idade), com o parâmetro fill=True para preencher a área sob a curva.
sns.kdeplot(df['idade'], fill=True)
Retorno da célula:
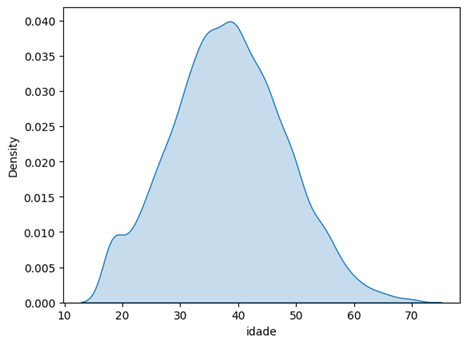
A distribuição acima é baseada em uma densidade. O KDE plot faz uma estimativa suave da função de densidade, que está relacionada à probabilidade dos dados.
A escolha entre histograma e KDE plot depende do que queremos mostrar. O histograma é ideal para intervalos com maior granularidade, enquanto o KDE plot é melhor para visualizações contínuas.
Outro gráfico importante é o boxplot, usado para analisar estatísticas descritivas. Para criá-lo, usamos a função boxplot(), passando a coluna idade como y e o DataFrame df como data.
sns.boxplot(y='idade', data=df)
Retorno da célula:
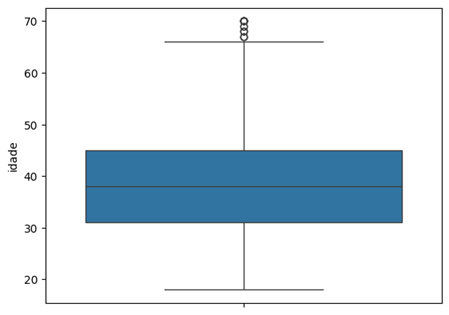
O boxplot mostra o primeiro quartil, a mediana e o terceiro quartil, além dos bigodes, linhas que indicam os valores mínimo e máximo. Os pontos fora dos bigodes são outliers.
Podemos comparar mais de uma variável no boxplot, como a idade (idade) em relação ao método de pagamento (metodo_pagamento). Isso nos permite visualizar diferenças de idade entre métodos como dinheiro, Pix, cartão e carteira digital.
Nesse caso, chamamos novamente a função boxplot(), mas definimos o x como metodo_pagamento. O y continuará como idade, assim como data será df.
sns.boxplot(x='metodo_pagamento', y='idade', data=df)
Retorno da célula:
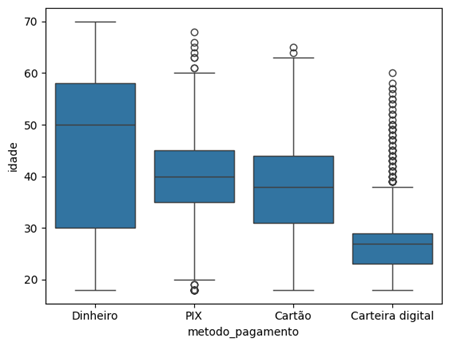
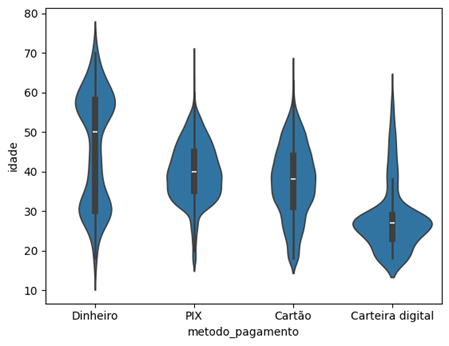
Note que há diferenças em relação à idade para cada método de pagamento. No dinheiro, por exemplo, a mediana está próxima da idade de 50 anos. Já em carteira digital, a mediana está mais próxima dos 30 anos. A partir desse gráfico, conseguimos realizar análises e obter vários insights.
Por fim, falaremos sobre o violin plot (ou gráfico de violino). Além de mostrar a distribuição dos dados, ele traz a forma e suavidade da distribuição.
Para plotar esse tipo de gráfico, utilizamos a função violinplot(), passando a variável metodo_pagamento para x e a coluna idade para y. O formato do violin plot lembra um violino, mostrando a suavidade da distribuição para cada categoria.
sns.violinplot(x='metodo_pagamento', y='idade', data=df)
Retorno da célula:
Para personalizar os gráficos, podemos adicionar títulos, rótulos aos eixos e ajustar o tamanho da figura. No código abaixo, aplicamos customizações básicas:
import matplotlib.pyplot as plt
# Definindo o tamanho da figura
plt.figure(figsize=(8, 4))
# Plotando o gráfico
sns.violinplot(x='metodo_pagamento', y='idade', data=df, hue='metodo_pagamento')
# Definindo o título do gráfico
plt.title('Violinplot da distribuição das idades por método de pagamento', loc='left', fontsize=14)
# Definindo a label do eixo x
plt.xlabel('Método de pagamento', fontsize=12)
# Definindo a label do eixo y
plt.ylabel('Idade', fontsize=12)
# Removendo a borda do gráfico
sns.despine()
# Exibindo o gráfico
plt.show()
Retorno da célula:
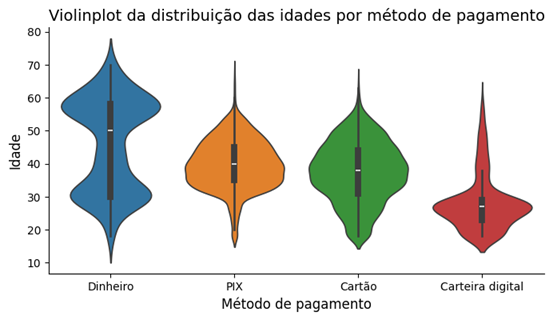
Começamos o código importando o módulo pyplot da biblioteca matplotlib. Depois, definimos o tamanho da figura com plt.figure(), especificando largura e altura com figsize. Além disso, definimos cores para cada categoria do método de pagamento e ajustamos outros detalhes visuais.
Após este vídeo, teremos uma série de exercícios para você praticar e aprimorar suas habilidades na criação de gráficos de distribuição. Nos encontramos em uma próxima oportunidade!
O curso Praticando gráficos: distribuição com Seaborn possui 13 minutos de vídeos, em um total de 13 atividades. Gostou? Conheça nossos outros cursos de Data Science em Data Science, ou leia nossos artigos de Data Science.
Matricule-se e comece a estudar com a gente hoje! Conheça outros tópicos abordados durante o curso:
Impulsione a sua carreira com os melhores cursos e faça parte da maior comunidade tech.
2 anos de Alura
Matricule-se no plano PLUS 24 e garanta:
Jornada de estudos progressiva que te guia desde os fundamentos até a atuação prática. Você acompanha sua evolução, entende os próximos passos e se aprofunda nos conteúdos com quem é referência no mercado.
Mobile, Programação, Front-end, DevOps, UX & Design, Marketing Digital, Data Science, Inovação & Gestão, Inteligência Artificial
Formações com mais de 1500 cursos atualizados e novos lançamentos semanais, em Programação, Inteligência Artificial, Front-end, UX & Design, Data Science, Mobile, DevOps e Inovação & Gestão.
A cada curso ou formação concluído, um novo certificado para turbinar seu currículo e LinkedIn.
No Discord, você participa de eventos exclusivos, pode tirar dúvidas em estudos colaborativos e ainda conta com mentorias em grupo com especialistas de diversas áreas.
Faça parte da maior comunidade Dev do país e crie conexões com mais de 120 mil pessoas no Discord.
Acesso ilimitado ao catálogo de Imersões da Alura para praticar conhecimentos em diferentes áreas.
Explore um universo de possibilidades na palma da sua mão. Baixe as aulas para assistir offline, onde e quando quiser.
Acelere o seu aprendizado com a IA da Alura e prepare-se para o mercado internacional.
2 anos de Alura
Todos os benefícios do PLUS 24 e mais vantagens exclusivas:
Luri é nossa inteligência artificial que tira dúvidas, dá exemplos práticos, corrige exercícios e ajuda a mergulhar ainda mais durante as aulas. Você pode conversar com a Luri até 100 mensagens por semana.
Aprenda um novo idioma e expanda seus horizontes profissionais. Cursos de Inglês, Espanhol e Inglês para Devs, 100% focado em tecnologia.
Para estudantes ultra comprometidos atingirem seu objetivo mais rápido.
2 anos de Alura
Todos os benefícios do PRO 24 e mais vantagens exclusivas:
Mensagens ilimitadas para estudar com a Luri, a IA da Alura, disponível 24hs para tirar suas dúvidas, dar exemplos práticos, corrigir exercícios e impulsionar seus estudos.
Envie imagens para a Luri e ela te ajuda a solucionar problemas, identificar erros, esclarecer gráficos, analisar design e muito mais.
Escolha os ebooks da Casa do Código, a editora da Alura, que apoiarão a sua jornada de aprendizado para sempre.
Conecte-se ao mercado com mentoria individual personalizada, vagas exclusivas e networking estratégico que impulsionam sua carreira tech para o próximo nível.






