

Boas-vindas ao curso de Skupper. Meu nome é Rafael Zago.
Audiodescrição: Rafael é uma pessoa branca. Tem olhos castanhos e cabeça raspada. Possui barba escura com fios grisalhos. Está sentado em seu escritório. Ao fundo, há alguma estante com livros de ficção científica e quadros de filmes.
Este curso é destinado a quem trabalha com deploy de aplicações em nuvem, pessoas desenvolvedoras multicloud ou cloud, que desejam realizar o deploy de uma aplicação distribuída de maneira segura.
Assim, você poderá criar uma aplicação capaz de operar em ambientes que não estão fisicamente conectados, como datacenters em regiões diferentes - ou até conectar uma aplicação legada ao seu cluster Kubernetes.
Nesta solução que vamos explorar, há alguns aspectos interessantes que devemos conhecer.
Primeiramente, vamos conhecer a aplicação distribuída com a qual vamos trabalhar. A aplicação básica terá três namespaces, os quais possuem diferentes aplicações em execução. Vamos realizar o deploy dessas aplicações em cada um dos namespaces, que simularão datacenters distintos.
Com essas aplicações implantadas, utilizaremos o Skupper para estabelecer a comunicação nativa entre elas de maneira quase nada invasiva. Além disso, conectaremos uma aplicação legada, que não opera no Kubernetes, dentro de um cluster Kubernetes de forma simples e ágil.
No nosso projeto, utilizaremos o Minikube para simular nosso ambiente multicloud. O Minikube terá namespaces para cada parte da nossa solução. Dessa maneira, os namespaces estarão isolados em comunicação. A comunicação entre eles será realizada através do Skupper.
Vamos introduzir um conceito em nossa solução chamada VAN (Virtual Application Network). Dessa forma, seremos capazes de entregar soluções distribuídas e outras geograficamente distintas.
Para aproveitar este curso, é interessante ter algumas noções sobre aplicações em nuvem (cloud-ready) e Kubernetes. Embora forneçamos todos os comandos necessários, é útil ter uma compreensão básica do que é o Kubernetes, além de familiaridade com Linux e ferramentas de linha de comando.
Não deixe de aproveitar outros recursos da nossa plataforma, como o fórum para tirar dúvidas e o Discord da Alura para interagir. Vamos estudar?
Vamos começar entendendo o problema que precisamos resolver. Para isso, é essencial contextualizar a solução que vamos entregar.
Vamos apresentar uma imagem retirada do site do Skupper para ilustrar melhor o conceito:
Pensemos em uma aplicação básica, composta por um front-end e um back-end. O back-end segue o padrão REST e é acessado pelo front-end.
Em uma implementação tradicional no Kubernetes, a aplicação é entregue por meio do acesso de pod front-end a um serviço dentro do namespace chamado back-end, utilizando a porta 8080. A aplicação funciona a partir dessa comunicação.
Agora, consideremos cenários mais complexos: um ambiente multicloud, onde não dependemos de um único cloud provider; um único cloud provider em diferentes regiões geográficas; ou um único datacenter, mas com necessidade de segregação entre as aplicações de front-end e back-end.
Dessa forma, o desafio central é:
Como garantir que o front-end continue acessando o serviço do back-end de forma transparente?
Nesse contexto, "transparente" significa que o front-end continuará chamando o serviço Kubernetes como se estivesse no mesmo namespace, e o back-end continuará respondendo às chamadas como se fossem serviços chamados através de aplicações dentro do mesmo namespace.
Existem diferentes abordagens para resolver esse problema. Pensando em datacenters separados, é possível criar uma VPN entre os dois datacenters. Isso envolve um certo trabalho de infraestrutura. Por exemplo, podemos usar serviços do cloud provider, que permitam a comunicação entre os dois datacenters, mas isso envolve um certo custo.
A escolha do Skupper foi baseada nos seguintes fatores:
Além disso, o Skupper é leve, escalável e transparente, tornando-se uma excelente opção para essa implementação.
Para resolver os problemas dos exemplos do curso, utilizaremos o Minikube como nosso cluster.
Na atividade de "Preparando o Ambiente", explicamos como instalar todas as ferramentas necessárias para o curso.
Agora, vamos validar as instalações no terminal. Para verificar se o Minikube está instalado, utilizaremos o seguinte comando:
minikube
Confirmamos que o binário está instalado, pois recebemos uma lista dos comandos disponíveis.
Também conferimos se a ferramenta do Kubectl está disponível, pois ele será utilizado para manipular o cluster:
kubectl
Além disso, utilizaremos o Podman para simular os nodes do cluster Kubernates, pois ele é mais leve e adequado para nossa configuração. Nesse caso, estamos usando um Linux com 4 GB de memória e dois núcleos para facilitar a reprodução.
Primeiramente, vamos iniciar o nosso cluster. Por enquanto, não vamos nos preocupar com namespaces ou qualquer outra configuração adicional.
Executamos o seguinte comando para iniciar o Minikube com o Podman:
minikube start --driver=podman
Assim que o processo for concluído, o terminal será liberado. Para validar a execução cluster usamos o seguinte comando:
minikube status
- type: Control Plane
- host: Running
- kubelet: Running
- apiserver: Running
- kubeconfig: Configured
Esse comando retorna o status do cluster e confirma que ele está funcional.
Com isso, podemos avançar para a simulação do ambiente multicloud. O arquivo de configuração pode ser encontrado no diretório:
ls ~/.kube/config
Esse arquivo contém os detalhes e recursos do cluster. Para a simulação do ambiente multicloud, precisaremos de dois arquivos de configuração distintos - independentemente se o cluster está separado por regiões ou não.
A partir de agora, vamos trabalhar com dois terminais — um para cada datacenter ou namespace.
No terminal, faremos uma cópia do KubeConfig para config-west e outro para config-east, que serão o front e back-end, respectivamente.
cp ~/.kube/config ~/.kube/config-west
cp ~/.kube/config ~/.kube/config-east
Dessa maneira, cada terminal vai apontar para um KubeConfig diferente e, assim, simular o multicloud.
Em seguida, configuramos cada terminal para utilizar um dos arquivos. Para isso, precisamos usar a variável KUBECONFIG que o Kubeclt lê por padrão.
No primeiro terminal (west):
export KUBECONFIG=~/.kube/config-west
No segundo terminal (east):
export KUBECONFIG=~/.kube/config-east
Agora, cada terminal opera de forma independente, simulando dois datacenters distintos. Para validar se a configuração está funcionando, podemos usar o comando:
kubectl get nodes
Agora, em cada terminal, vamos criar a infraestrutura correspondente.
No primeiro terminal (west), criamos um namespace chamado west.
kubectl create namespace west
namespace/west created
Em seguida, definimos o contexto do Kubectl para que ele use esse namespace por padrão:
kubectl config set-context --current --namespace=west
Context 'minikube' modified
Depois de modificar o contexto, podemos usar um comando para validar a configuração:
kubectl get pods
No resources found in west namespace.
Com isso, o terminal avisa que não encontrou nenhum recurso no namespace west. Isso significa que esse terminou já entendeu qual é o local que ele está trabalhando.
Da mesma maneira, vamos criar um namespace chamado east no segundo terminal, que teoricamente acessa outro cluster.
kubectl create namespace east
namespace/east created
Em seguida, vamos setar o contexto do Kubectl para o east.
kubectl config set-context --current --namespace=east
Context 'minikube' modified
Podemos validar a configuração executando:
kubectl get pods
No resources found in east namespace.
Como esperado, não há recursos rodando ainda no namespace east.
Com isso, criamos a estrutura de dois datacenters para simular um ambiente multicloud. A seguir, vamos fazer a instalação do Skupper e as demais ferramentas necessárias.
Agora que já temos nosso ambiente configurado, pelo menos inicialmente, vamos entender exatamente o que criamos e o que precisamos evoluir para que o Skupper funcione adequadamente. Ainda há bastante para explorar, então começaremos entendendo nosso ambiente.
Neste diagrama, vamos compreender o que já foi feito. Apesar de ter apenas um cluster rodando com namespaces distintos, vamos considerar o cluster 1 e o cluster 2 para fazer a simulação multicloud.
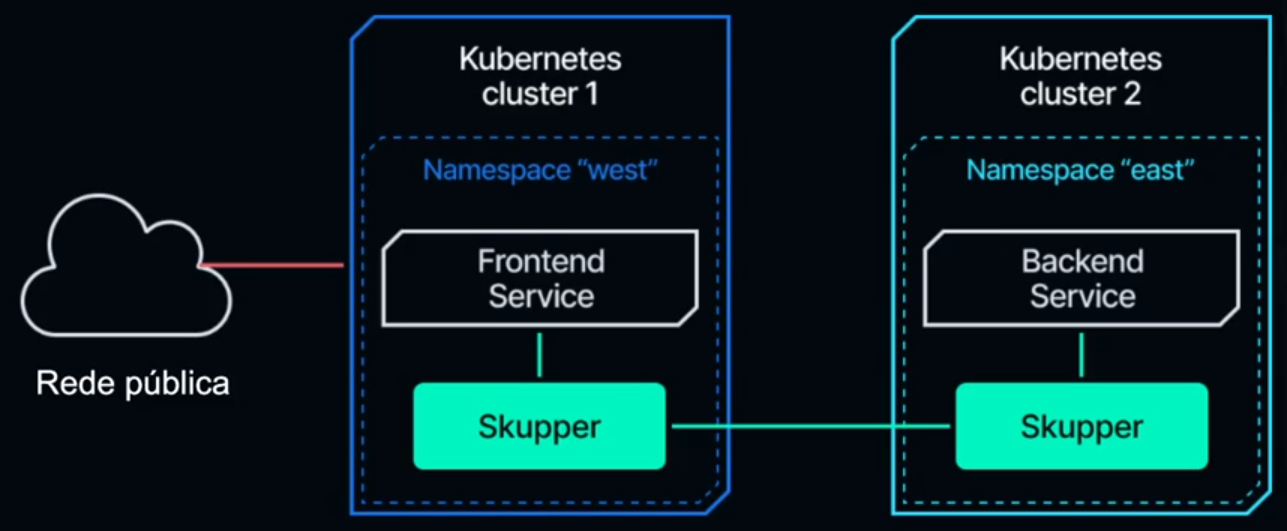
Logicamente, separamos o namespace west no cluster 1 e o namespace east no cluster 2. Se você for executar este exemplo no dia a dia, você pode usar clusters distintos. O único requisito é que um deles tenha acesso direto à internet. Isso está relacionado a como vamos conectar os dois namespaces.
Com isso, vamos introduzir um conceito que usaremos daqui para frente. Para o Skupper, um cluster dentro de um namespace recebe o nome de site. Não é site de website nem de localização física, embora possa ser localização física, mas não necessariamente. Então, agora temos dois sites: o site west e o site east.
Dentro desses sites, teremos duas aplicações (deployments) em execução. No west, teremos o front-end, ou seja, a aplicação web rodando. Enquanto, no east teremos o back-end. Eles estão como serviços, mas compõem todo um deployment, um componente de configuração comum do Kubernetes.
Para que ambos consigam se comunicar, o Skupper estabelecerá uma comunicação entre esses dois datacenters através da camada 7.
Até agora, criamos cluster 1 (site west) e o cluster 2 (site east). Para evoluir a configuração, antes de fazer o deploy de aplicações ou nos preocuparmos com serviços, vamos instalar o Skupper binário, que chamamos de CLI (Command Line Interface).
Assim como o Kubectl é o CLI para manipular elementos do Kubernetes, o Skupper também possui seu próprio CLI para manipular seus componentes.
Da mesma máquina, manipulemos clusters distintos. Por isso, o CLI só precisa estar instalado em uma máquina.
Para fazer essa instalação, seguiremos as instruções do site do Skupper. No menu "Getting Started", encontramos os requisitos e os passos para começar com o Skupper. Vamos copiar o comando para instalar a linha de comando no nosso ambiente e colá-lo no terminal. Não importa qual lado, desde que a mesma máquina controle ambos.
curl https://skupper.io/install.sh | sh
The Skupper command is now installed.
- Version:
1.8.3- Path:
/home/aluno/.local/bin/skupper
Com isso, fazemos o download CLI na versão 1.8.3 e o movemos para o diretório /home/seu_usuario/.local/bin/skupper. Agora, precisamos acessar o arquivo através de uma linha de exportação para tê-lo disponível no nosso path.
Antes de fazer o export, é importante entender as versões do Skupper. A versão 1.8 é a mais atual disponível para o usuário no site do Skupper Upstream. O Skupper é um produto da Red Hat, mas é open source. Podemos comparar com o Fedora e o Red Hat Enterprise Linux, onde o Fedora é open source e upstream, enquanto o Enterprise Linux é downstream. Não utilizaremos nada pago ou registrado, mas sim a versão 1.8 upstream, que é a última versão.
Podemos conferir que o Skupper está instalado no path com o comando:
skupper version
- client version
1.8.3- transport version
not-found- controller version
not-found- config-sync version
not-found- flow-collector version
not-found
O Skupper não é invasivo, não possui sidecars, mas tem seus componentes. Três deles são importantes: o controller, o config-sync e o flow-collector. Esses três containers são responsáveis por conectar os dois lados da aplicação, sincronizar as configurações dos dois lados quando os serviços forem expostos e coletar estatísticas na rede VAN (Virtual Application Network).
Há uma função que conheceremos mais adiante, um console web para visualizar as conexões e como a configuração foi feita pelo Skupper. No momento, os componentes aparecem como "não encontrado" porque apenas o CLI do Skupper está instalado; os componentes do Kubernetes ainda não foram instalados.
Podemos executar o comando skupper para conferir as várias funções que usaremos em nossos exemplos, que vão nos permitir vincular os dois sites e expor serviços, tornando nosso desenho de solução coerente.
skupper
Available Commands
completion: output shell completion code for bashdebug: debug skupper installationdelete: delete skupper installationexpose: expose a set of pods through a Skupper addressgateway: manage skupper gateway definitionshelp: help about any command ...
Vamos revisar o desenho de solução para entender melhor. Entre um site e outro, haverá um sincronizador de configurações, um controller com um router dentro dele. Basicamente, esse router funciona como um roteador de internet, mas roda dentro de um container, e possibilita a comunicação entre os dois lados.
Agora que o CLI está instalado e nosso ambiente configurado, a próxima etapa é habilitar o Skupper em cada um dos nossos sites. Até breve!
O curso Skupper: fazendo o deploy de aplicações Multicloud possui 108 minutos de vídeos, em um total de 32 atividades. Gostou? Conheça nossos outros cursos de Google Cloud Platform em DevOps, ou leia nossos artigos de DevOps.
Matricule-se e comece a estudar com a gente hoje! Conheça outros tópicos abordados durante o curso:
Impulsione a sua carreira com os melhores cursos e faça parte da maior comunidade tech.
2 anos de Alura
Matricule-se no plano PLUS 24 e garanta:
Jornada de estudos progressiva que te guia desde os fundamentos até a atuação prática. Você acompanha sua evolução, entende os próximos passos e se aprofunda nos conteúdos com quem é referência no mercado.
Mobile, Programação, Front-end, DevOps, UX & Design, Marketing Digital, Data Science, Inovação & Gestão, Inteligência Artificial
Formações com mais de 1500 cursos atualizados e novos lançamentos semanais, em Programação, Inteligência Artificial, Front-end, UX & Design, Data Science, Mobile, DevOps e Inovação & Gestão.
A cada curso ou formação concluído, um novo certificado para turbinar seu currículo e LinkedIn.
No Discord, você participa de eventos exclusivos, pode tirar dúvidas em estudos colaborativos e ainda conta com mentorias em grupo com especialistas de diversas áreas.
Faça parte da maior comunidade Dev do país e crie conexões com mais de 120 mil pessoas no Discord.
Acesso ilimitado ao catálogo de Imersões da Alura para praticar conhecimentos em diferentes áreas.
Explore um universo de possibilidades na palma da sua mão. Baixe as aulas para assistir offline, onde e quando quiser.
Acelere o seu aprendizado com a IA da Alura e prepare-se para o mercado internacional.
2 anos de Alura
Todos os benefícios do PLUS 24 e mais vantagens exclusivas:
Luri é nossa inteligência artificial que tira dúvidas, dá exemplos práticos, corrige exercícios e ajuda a mergulhar ainda mais durante as aulas. Você pode conversar com a Luri até 100 mensagens por semana.
Aprenda um novo idioma e expanda seus horizontes profissionais. Cursos de Inglês, Espanhol e Inglês para Devs, 100% focado em tecnologia.
Para estudantes ultra comprometidos atingirem seu objetivo mais rápido.
2 anos de Alura
Todos os benefícios do PRO 24 e mais vantagens exclusivas:
Mensagens ilimitadas para estudar com a Luri, a IA da Alura, disponível 24hs para tirar suas dúvidas, dar exemplos práticos, corrigir exercícios e impulsionar seus estudos.
Envie imagens para a Luri e ela te ajuda a solucionar problemas, identificar erros, esclarecer gráficos, analisar design e muito mais.
Escolha os ebooks da Casa do Código, a editora da Alura, que apoiarão a sua jornada de aprendizado para sempre.
Conecte-se ao mercado com mentoria individual personalizada, vagas exclusivas e networking estratégico que impulsionam sua carreira tech para o próximo nível.






